Grandi moli di dati e nuovi metodi e tecnologie per analizzarli. La nuova frontiera del machine learning al servizio degli studi sul clima e della valutazione del rischio, in una ricerca di Fondazione CMCC e Università Ca’ Foscari Venezia

Venezia, 18 novembre 2021 – Il riscaldamento globale sta inasprendo il verificarsi di eventi meteorologici e climatici estremi. L’interazione tra le diverse forme di pericolo innescate dai cambiamenti climatici ci farà assistere, nel prossimo futuro, ad impatti trasversali su diversi settori e sistemi naturali e antropici.
Il mondo della ricerca può aiutare a comprendere tali interazioni e dinamiche, supportando i decisori nella gestione dei rischi attuali e futuri, anche grazie ad una migliore capacità di prevedere i rischi attesi e quantificarne i potenziali impatti.
A questo scopo, negli ultimi anni, la comunità scientifica ha iniziato a testare nuovi approcci metodologici, tecnologie e strumenti, tra i quali emerge l’applicazione del machine learning, in grado di sfruttare il potenziale della grande mole e varietà di dati ad oggi disponibile per il monitoraggio ambientale.
A cosa sta portando l’incremento esponenziale di ricerche sull’applicazione dei metodi di machine learning alla valutazione dei rischi indotti dai cambiamenti climatici?
Un team di scienziati di Fondazione CMCC ed Università Ca’ Foscari Venezia, nello studio “Exploring machine learning potential for climate change risk assessment” ha risposto a questa domanda attraverso una revisione approfondita di oltre 1200 articoli sul tema pubblicati negli ultimi 20 anni, che ha messo in luce potenzialità e limiti del machine learning in questo ambito.
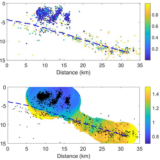
“Il machine learning è una branca dell’intelligenza artificiale – spiega Federica Zennaro, ricercatrice alla Fondazione CMCC e all’Università Ca’ Foscari Venezia e primo autore dello studio – Simulando i processi del cervello umano, alcuni algoritmi matematici sono in grado di comprendere le relazioni tra una serie di dati di input al fine di predire l’output richiesto. Nella nostra ricerca abbiamo individuato che inondazioni e frane sono gli eventi più analizzati attraverso modelli di machine learning, probabilmente anche perché i più rilevanti e frequenti a livello globale”.
Il machine learning, emerge dallo studio, ha due grandi potenzialità che lo rendono particolarmente interessante se applicato a questo settore.
La prima è che questi algoritmi riescono ad imparare dai dati: più dati ha a disposizione, più l’algoritmo impara. Grazie alla sua capacità di analizzare ed elaborare grandi quantità di dati, il machine learning permette di dipanare relazioni complesse sottese al funzionamento dei sistemi socio-ecologici, sfruttando l’enorme disponibilità di dati (big data) che arrivano oggi da varie fonti, tra cui sensori per analisi ambientali ad alta frequenza temporale, social media, dati ed immagini satellitari, droni.
La seconda è che possono combinare dati di diverso tipo, riuscendo quindi a valutare l’entità di un rischio tenendo conto di tutte le sue dimensioni, che non comprendono solamente il pericolo che lo innesca (ad esempio un aumento delle precipitazioni), ma anche la vulnerabilità e l’esposizione del sistema socio-economico su cui il pericolo si abbatte, fattori determinanti nella quantificazione degli impatti.
“Per fare un esempio, se il modello viene addestrato con dati dettagliati sugli eventi di inondazione degli ultimi 20 anni, includendo la loro posizione e l’indicazione del tipo di contesto (urbano o naturale) interessato, il modello è in grado di proiettare, in uno scenario dato da condizioni climatiche future, quale sarà la probabilità che un evento accada in un certo punto, e calcolarne il rischio di provocare impatti dannosi per la società e l’ambiente – spiega Zennaro – Il machine learning rappresenta il futuro del settore della valutazione del rischio, ma le sue grandi potenzialità non sono ancora sfruttate ampiamente. Dalla nostra ricerca emerge che è ancora molto ridotto il numero di studi che utilizzano questi modelli per l’elaborazione di scenari di rischio futuri di lungo termine (con orizzonte il 2100). La stragrande maggioranza si focalizza sul breve periodo, probabilmente influenzata dalla ridotta disponibilità di serie temporali estese, capaci di supportare un adeguato addestramento del modello per proiezioni su lungo termine”.
Il prossimo passo, spiega Elisa Furlan, ricercatrice alla Fondazione CMCC e all’Università Ca’ Foscari Venezia e tra gli autori dello studio, è quello di sviluppare modelli di machine learning che siano sempre più capaci di studiare e districare le complesse interrelazioni spazio-temporali tra diverse variabili climatiche, ambientali e socio-economiche, migliorando così la comprensione del comportamento dei sistemi complessi.
“In vista della crescente abbondanza dei dati a disposizione nonché della complessità dei modelli di machine learning, il mondo della ricerca avrà la possibilità (e il dovere) di migliorare la comprensione dei rischi legati ai cambiamenti climatici, con l’obiettivo principale di fornire scenari multi-rischio accurati ed affidabili, che siano in grado di guidare una solida pianificazione dell’adattamento e la gestione e riduzione del rischio di catastrofi”, conclude Furlan.
 Salva come PDF
Salva come PDF